
In this post, using pandas we will understand more about fan’s choice on favourite star war’s characters, films etc:-
import pandas as pd
star_wars = pd.read_csv("star_wars.csv", encoding = 'ISO-8859-1')
star_wars.head(10)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
star_wars.columns
Index(['RespondentID',
'Have you seen any of the 6 films in the Star Wars franchise?',
'Do you consider yourself to be a fan of the Star Wars film franchise?',
'Which of the following Star Wars films have you seen? Please select all that apply.',
'Unnamed: 4', 'Unnamed: 5', 'Unnamed: 6', 'Unnamed: 7', 'Unnamed: 8',
'Please rank the Star Wars films in order of preference with 1 being your favorite film in the franchise and 6 being your least favorite film.',
'Unnamed: 10', 'Unnamed: 11', 'Unnamed: 12', 'Unnamed: 13',
'Unnamed: 14',
'Please state whether you view the following characters favorably, unfavorably, or are unfamiliar with him/her.',
'Unnamed: 16', 'Unnamed: 17', 'Unnamed: 18', 'Unnamed: 19',
'Unnamed: 20', 'Unnamed: 21', 'Unnamed: 22', 'Unnamed: 23',
'Unnamed: 24', 'Unnamed: 25', 'Unnamed: 26', 'Unnamed: 27',
'Unnamed: 28', 'Which character shot first?',
'Are you familiar with the Expanded Universe?',
'Do you consider yourself to be a fan of the Expanded Universe?Âæ',
'Do you consider yourself to be a fan of the Star Trek franchise?',
'Gender', 'Age', 'Household Income', 'Education',
'Location (Census Region)'],
dtype='object')
# Removing NaN rows of RespondentIDs
print(star_wars.shape)
star_wars = star_wars[pd.notnull(star_wars['RespondentID'])]
print(star_wars.shape)
(1187, 38)
(1186, 38)
yes_no = {
"Yes" : True,
"No" : False,
}
cols = ['Have you seen any of the 6 films in the Star Wars franchise?', 'Do you consider yourself to be a fan of the Star Wars film franchise?']
for col in cols:
star_wars[col] = star_wars[col].map(yes_no)
star_wars.head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
seen_movies = star_wars.columns[3:9]
print(seen_movies)
Index(['Which of the following Star Wars films have you seen? Please select all that apply.',
'Unnamed: 4', 'Unnamed: 5', 'Unnamed: 6', 'Unnamed: 7', 'Unnamed: 8'],
dtype='object')
import numpy as np
movie_mapping = {
"Star Wars: Episode I The Phantom Menace": True,
np.nan: False,
"Star Wars: Episode II Attack of the Clones": True,
"Star Wars: Episode III Revenge of the Sith": True,
"Star Wars: Episode IV A New Hope": True,
"Star Wars: Episode V The Empire Strikes Back": True,
"Star Wars: Episode VI Return of the Jedi": True
}
for col in star_wars.columns[3:9]:
star_wars[col] = star_wars[col].map(movie_mapping)
star_wars = star_wars.rename(columns={
"Which of the following Star Wars films have you seen? Please select all that apply.": "seen_1",
"Unnamed: 4": "seen_2",
"Unnamed: 5": "seen_3",
"Unnamed: 6": "seen_4",
"Unnamed: 7": "seen_5",
"Unnamed: 8": "seen_6"
})
star_wars.head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
star_wars = star_wars.rename(columns={
"Please rank the Star Wars films in order of preference with 1 being your favorite film in the franchise and 6 being your least favorite film.": "ranking_1",
"Unnamed: 10": "ranking_2",
"Unnamed: 11": "ranking_3",
"Unnamed: 12": "ranking_4",
"Unnamed: 13": "ranking_5",
"Unnamed: 14": "ranking_6"
})
star_wars.head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
star_wars[star_wars.columns[9:15]] = star_wars[star_wars.columns[9:15]].astype(float)
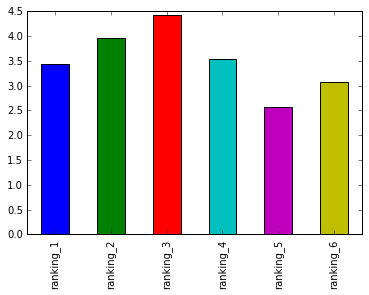
ranking_films = star_wars[star_wars.columns[9:15]].mean()
%matplotlib inline
ranking_films.plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x7fcf794a74a8>
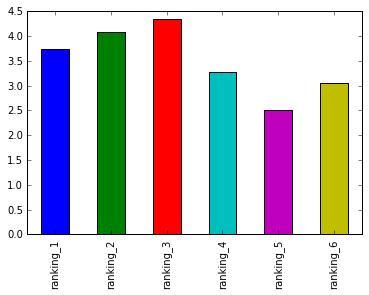
Ranking
So far, we have cleaned the data, column names. It should be noted that the films in 1, 2, 3 are relatively modern movies, where as movies in 4, 5, 6 columns are older generation movies in 77, 80 and 83 respectively. As expected, these ranked higher than the newer movies.
The most viewd movie in the StarWars Series is
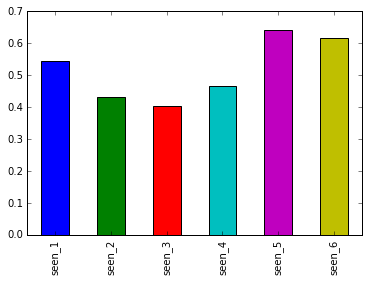
most_seen_films = star_wars[star_wars.columns[3:9]].sum()
print(most_seen_films)
most_seen_films.plot.bar()
seen_1 673
seen_2 571
seen_3 550
seen_4 607
seen_5 758
seen_6 738
dtype: int64
<matplotlib.axes._subplots.AxesSubplot at 0x7fcf77398470>
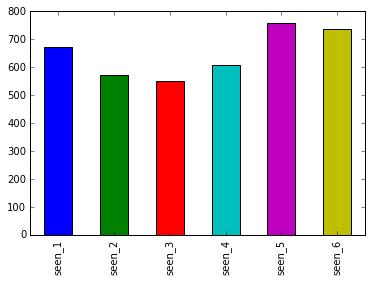
View counts
It looks like the older movies in the series is watched more than the newer movies of the series. This is consistent with what we have observed in the rankings
Does Males and Females like different sets of movies in the StarWars series?
males = star_wars[star_wars['Gender'] == 'Male']
females = star_wars[star_wars['Gender'] == 'Female']
print(males.shape[0], females.shape[0])
497 549
Interesting: I expected number of males to be higher than the Females
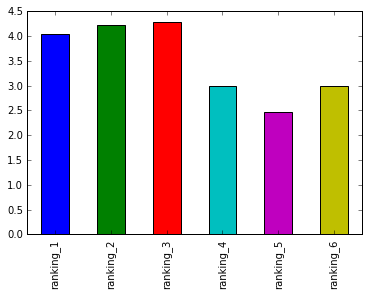
Most liked and seen movie in the Series by Males
males_ranking_films = males[males.columns[9:15]].mean()
males_ranking_films.plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x7fcf7704b240>
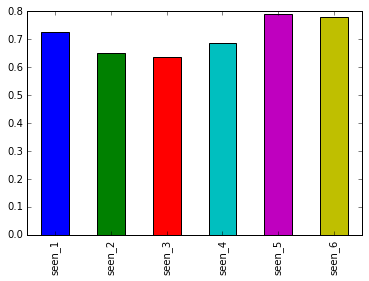
males_seen_films = males[males.columns[3:9]].mean()
males_seen_films.plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x7fcf76fe4978>
Most liked and seen movie in the Series by Females
females_ranking_films = females[females.columns[9:15]].mean()
females_ranking_films.plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x7fcf76ecdc50>
females_seen_films = females[females.columns[3:9]].mean()
females_seen_films.plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x7fcf76e44748>
Observations:
- Both Male and Female viewers show the overall trend. Both sets of viewers like and watched older movies in the series more the newer movies